#Json API Integration
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text
Travelport JSON API Integration by Infinity Webinfo Pvt Ltd: Revolutionizing Travel Booking Systems

The travel industry has undergone a significant transformation with the advent of digital technologies. Online travel platforms, travel agencies, and tech companies now require advanced and seamless booking systems to cater to modern travelers' expectations. Travelport, a leading global travel technology company, has addressed this demand by offering its JSON API—a flexible, developer-friendly interface designed to integrate diverse travel services into web and mobile applications. This API opens the door to vast travel content, enabling real-time bookings, ticketing, and other travel-related services.
Infinity Webinfo Pvt Ltd, a expert web and software development firm, has recognized this need by providing Travelport JSON API integration services, enabling travel agencies, OTAs (Online Travel Agencies), and travel tech platforms to offer comprehensive and seamless booking experiences to their users.
Travelport Json API Integration API Integration by Infinity Webinfo Pvt Ltd
What is Travelport JSON API?
The Travelport JSON API allows businesses to connect with and access Travelport’s wide-ranging travel content. Travelport has established relationships with airlines, hotels, car rental companies, and other travel service providers. By using the JSON API, businesses can tap into this network, offering real-time inventory and pricing to customers.
The API uses JavaScript Object Notation (JSON) as its data format, which is lightweight and easy to handle. This makes it an ideal choice for both web-based applications and mobile platforms, ensuring faster communication and better performance compared to heavier, older formats like XML.
Key Features of Travelport JSON API
Flight Booking: Travelport JSON API offers access to comprehensive flight data, including schedules, availability, and pricing for airlines worldwide. Developers can integrate search, booking, and ticketing capabilities, allowing users to find and book flights efficiently.
Hotel Booking: JSON API allows seamless hotel bookings by providing access to hotel availability, pricing, and room details from various suppliers. Users can search for hotels by location, check available rooms, view rates, and complete their bookings in real-time.
Car Rentals: JSON API offers real-time access to car rental services, enabling users to browse different car options based on their travel preferences. Users can filter cars by location, supplier, availability, and pricing, and make reservations instantly.
PNR (Passenger Name Record) Management: One of the most critical elements in travel booking is the PNR. With Travelport JSON API, businesses can create, manage, and modify PNRs efficiently. This includes handling multiple travel segments (flights, hotels, cars), passenger details, and fare information.
Ancillaries: The API supports booking ancillary services like baggage, seat selection, in-flight meals, and priority boarding. This feature helps businesses upsell additional services to travelers, enhancing both user experience and revenue.
Fare Quotes and Ticketing: Fare quotes are a crucial part of any booking engine. The Travelport JSON API allows businesses to retrieve up-to-the-minute fare information and enables ticketing directly through the platform. The API also supports fare rule retrieval for refund or change policies.
Benefits of Integrating Travelport JSON API
Real-Time Inventory: One of the most significant advantages of integrating Travelport’s JSON API By INFINITY WEBINFO PVT LTD is access to real-time inventory from multiple airlines, hotels, and car rental companies. Users can search and book travel services without delays or discrepancies in pricing and availability.
Enhanced User Experience: By integrating the Travelport JSON API, businesses can deliver an optimized and intuitive user experience. The API's lightweight structure ensures fast data retrieval, which enhances user interactions, especially on mobile platforms where speed is critical.
Comprehensive Travel Services: The API consolidates multiple travel services into one platform. Businesses can offer users an all-in-one solution for flights, hotels, car rentals, and ancillary services, eliminating the need to manage multiple systems or providers.
Customizable Search Options: The Travelport JSON API allows for tailored search filters based on user preferences. Users can search for flights by airline, cabin class, price range, stops, or other criteria. Similarly, hotels and cars can be filtered by location, amenities, and pricing, offering flexibility and a personalized experience.
Scalable and Flexible: The API is highly scalable, allowing travel platforms to grow their offerings over time. Whether expanding into new markets or adding more services, businesses can easily scale their system without major overhauls.
Cost Efficiency: Using a JSON-based API reduces overhead costs as it requires less bandwidth than heavier formats like XML. Additionally, with its easy-to-parse structure, it speeds up development, allowing faster time-to-market for new features and integrations.
Why Choose Infinity Webinfo Pvt Ltd?
INFINITY WEBINFO PVT LTD stands out for its personalized approach to Travelport API integration. With a focus on collaboration, they work closely with clients to ensure that every detail aligns with business needs. Their technical expertise, coupled with an in-depth understanding of the travel industry, makes them a trusted partner for travel businesses looking to implement Travelport's capabilities into their offerings.
Conclusion
Integrating the Travelport JSON API is a game-changer for travel businesses looking to provide comprehensive and real-time travel services on their platforms. With a lightweight, flexible, and developer-friendly interface, the API simplifies access to flights, hotels, and car rentals, enabling businesses to offer their customers a seamless booking experience. From efficient PNR management to upselling ancillary services, Travelport’s API equips travel platforms with everything they need to stay competitive in today’s fast-paced travel market.
contacts us now:- Mobile: - +91 9711090237
#Travelporta json API Integration#Travelport API Integration#Json API Integration#Travelport#json#API Integration#infinity webinfo pvt ltd
1 note
·
View note
Text
Unlocking the Power of WP REST API: A Comprehensive Guide
Why Should You Use the WP REST API? The WP REST API is a powerful tool that allows you to interact with your WordPress site’s data and functionality using the JSON format. Whether you’re a developer, designer, or site owner, understanding and utilizing the capabilities of the WP REST API can greatly enhance your WordPress experience. Here are some key reasons why you should consider using the WP…
#API Integration#development#JSON#plugins#REST API#website development#WordPress#WordPress Development#WordPress REST API
0 notes
Text
Take a look at this post… 'JSON to XML and XML to JSON converter in second . Use it for API integrations and Web development projects'.
0 notes
Text
This blog whole heartedly endorses writing your own shit, open sourcing it as your own years before using it in a work context, and then safely saving yourself the trouble of writing it again at work.
You get a lot of things from that:
1. You're protecting your ability to build off your own work, regardless of who is paying you.
2. You're learning how to use your work in a business context. And while they may be able to claim the derivative works, they can't claim the experience of making them, or your reimplementing them back into the open source (with learned experience they paid for (without looking at the derivative code))
3. You protect your portfolio. This is probably the most important: here's this thing I made, here are the business critical things it runs or supports.
Me, I made a silly curl wrapper to send and receive json from the RuneScape auction house API, now it's running in two ERP/E-commerce integrations about to be deployed company wide as our standard for API integrations. It's also running at least one Instagram integration for a ski resort and some event ticketing thing for a local theater. It's also been used for proof of concept demonstrations of security vulnerabilities.
Clients love it when you show them the picture of a kitten that has a PHP shell in it and then proceed to read them their email through the kitten shell. By love I mean no one actually liked that and I deployed the fix server wide anyway because we were hemorrhaging money on preventable security breaches.
8 notes
·
View notes
Text

Wielding Big Data Using PySpark
Introduction to PySpark
PySpark is the Python API for Apache Spark, a distributed computing framework designed to process large-scale data efficiently. It enables parallel data processing across multiple nodes, making it a powerful tool for handling massive datasets.
Why Use PySpark for Big Data?
Scalability: Works across clusters to process petabytes of data.
Speed: Uses in-memory computation to enhance performance.
Flexibility: Supports various data formats and integrates with other big data tools.
Ease of Use: Provides SQL-like querying and DataFrame operations for intuitive data handling.
Setting Up PySpark
To use PySpark, you need to install it and set up a Spark session. Once initialized, Spark allows users to read, process, and analyze large datasets.
Processing Data with PySpark
PySpark can handle different types of data sources such as CSV, JSON, Parquet, and databases. Once data is loaded, users can explore it by checking the schema, summary statistics, and unique values.
Common Data Processing Tasks
Viewing and summarizing datasets.
Handling missing values by dropping or replacing them.
Removing duplicate records.
Filtering, grouping, and sorting data for meaningful insights.
Transforming Data with PySpark
Data can be transformed using SQL-like queries or DataFrame operations. Users can:
Select specific columns for analysis.
Apply conditions to filter out unwanted records.
Group data to find patterns and trends.
Add new calculated columns based on existing data.
Optimizing Performance in PySpark
When working with big data, optimizing performance is crucial. Some strategies include:
Partitioning: Distributing data across multiple partitions for parallel processing.
Caching: Storing intermediate results in memory to speed up repeated computations.
Broadcast Joins: Optimizing joins by broadcasting smaller datasets to all nodes.
Machine Learning with PySpark
PySpark includes MLlib, a machine learning library for big data. It allows users to prepare data, apply machine learning models, and generate predictions. This is useful for tasks such as regression, classification, clustering, and recommendation systems.
Running PySpark on a Cluster
PySpark can run on a single machine or be deployed on a cluster using a distributed computing system like Hadoop YARN. This enables large-scale data processing with improved efficiency.
Conclusion
PySpark provides a powerful platform for handling big data efficiently. With its distributed computing capabilities, it allows users to clean, transform, and analyze large datasets while optimizing performance for scalability.
For Free Tutorials for Programming Languages Visit-https://www.tpointtech.com/
2 notes
·
View notes
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
AvatoAI Review: Unleashing the Power of AI in One Dashboard

Here's what Avato Ai can do for you
Data Analysis:
Analyze CV, Excel, or JSON files using Python and libraries like pandas or matplotlib.
Clean data, calculate statistical information and visualize data through charts or plots.
Document Processing:
Extract and manipulate text from text files or PDFs.
Perform tasks such as searching for specific strings, replacing content, and converting text to different formats.
Image Processing:
Upload image files for manipulation using libraries like OpenCV.
Perform operations like converting images to grayscale, resizing, and detecting shapes or
Machine Learning:
Utilize Python's machine learning libraries for predictions, clustering, natural language processing, and image recognition by uploading
Versatile & Broad Use Cases:
An incredibly diverse range of applications. From creating inspirational art to modeling scientific scenarios, to designing novel game elements, and more.
User-Friendly API Interface:
Access and control the power of this advanced Al technology through a user-friendly API.
Even if you're not a machine learning expert, using the API is easy and quick.
Customizable Outputs:
Lets you create custom visual content by inputting a simple text prompt.
The Al will generate an image based on your provided description, enhancing the creativity and efficiency of your work.
Stable Diffusion API:
Enrich Your Image Generation to Unprecedented Heights.
Stable diffusion API provides a fine balance of quality and speed for the diffusion process, ensuring faster and more reliable results.
Multi-Lingual Support:
Generate captivating visuals based on prompts in multiple languages.
Set the panorama parameter to 'yes' and watch as our API stitches together images to create breathtaking wide-angle views.
Variation for Creative Freedom:
Embrace creative diversity with the Variation parameter. Introduce controlled randomness to your generated images, allowing for a spectrum of unique outputs.
Efficient Image Analysis:
Save time and resources with automated image analysis. The feature allows the Al to sift through bulk volumes of images and sort out vital details or tags that are valuable to your context.
Advance Recognition:
The Vision API integration recognizes prominent elements in images - objects, faces, text, and even emotions or actions.
Interactive "Image within Chat' Feature:
Say goodbye to going back and forth between screens and focus only on productive tasks.
Here's what you can do with it:
Visualize Data:
Create colorful, informative, and accessible graphs and charts from your data right within the chat.
Interpret complex data with visual aids, making data analysis a breeze!
Manipulate Images:
Want to demonstrate the raw power of image manipulation? Upload an image, and watch as our Al performs transformations, like resizing, filtering, rotating, and much more, live in the chat.
Generate Visual Content:
Creating and viewing visual content has never been easier. Generate images, simple or complex, right within your conversation
Preview Data Transformation:
If you're working with image data, you can demonstrate live how certain transformations or operations will change your images.
This can be particularly useful for fields like data augmentation in machine learning or image editing in digital graphics.
Effortless Communication:
Say goodbye to static text as our innovative technology crafts natural-sounding voices. Choose from a variety of male and female voice types to tailor the auditory experience, adding a dynamic layer to your content and making communication more effortless and enjoyable.
Enhanced Accessibility:
Break barriers and reach a wider audience. Our Text-to-Speech feature enhances accessibility by converting written content into audio, ensuring inclusivity and understanding for all users.
Customization Options:
Tailor the audio output to suit your brand or project needs.
From tone and pitch to language preferences, our Text-to-Speech feature offers customizable options for the truest personalized experience.
>>>Get More Info<<<
#digital marketing#Avato AI Review#Avato AI#AvatoAI#ChatGPT#Bing AI#AI Video Creation#Make Money Online#Affiliate Marketing
3 notes
·
View notes
Text
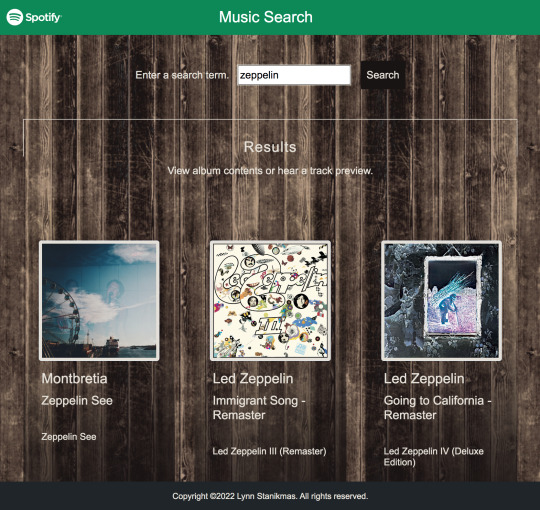






Angular SPA integrated with the Spotify Web API returns JSON metadata about music artists, albums, and tracks, directly from the Spotify Data Catalogue.
#angular#spotify#my music#firebase#firestore#data#database#backend#html5#frontend#coding#responsive web design company#responsivewebsite#responsivedesign#responsive web development#web development#web developers#software development#software#development#information technology#developer#technology#engineering#ui ux development services#ui#ui ux design#uidesign#ux#user interface
2 notes
·
View notes
Text
Advanced Techniques in Full-Stack Development

Certainly, let's delve deeper into more advanced techniques and concepts in full-stack development:
1. Server-Side Rendering (SSR) and Static Site Generation (SSG):
SSR: Rendering web pages on the server side to improve performance and SEO by delivering fully rendered pages to the client.
SSG: Generating static HTML files at build time, enhancing speed, and reducing the server load.
2. WebAssembly:
WebAssembly (Wasm): A binary instruction format for a stack-based virtual machine. It allows high-performance execution of code on web browsers, enabling languages like C, C++, and Rust to run in web applications.
3. Progressive Web Apps (PWAs) Enhancements:
Background Sync: Allowing PWAs to sync data in the background even when the app is closed.
Web Push Notifications: Implementing push notifications to engage users even when they are not actively using the application.
4. State Management:
Redux and MobX: Advanced state management libraries in React applications for managing complex application states efficiently.
Reactive Programming: Utilizing RxJS or other reactive programming libraries to handle asynchronous data streams and events in real-time applications.
5. WebSockets and WebRTC:
WebSockets: Enabling real-time, bidirectional communication between clients and servers for applications requiring constant data updates.
WebRTC: Facilitating real-time communication, such as video chat, directly between web browsers without the need for plugins or additional software.
6. Caching Strategies:
Content Delivery Networks (CDN): Leveraging CDNs to cache and distribute content globally, improving website loading speeds for users worldwide.
Service Workers: Using service workers to cache assets and data, providing offline access and improving performance for returning visitors.
7. GraphQL Subscriptions:
GraphQL Subscriptions: Enabling real-time updates in GraphQL APIs by allowing clients to subscribe to specific events and receive push notifications when data changes.
8. Authentication and Authorization:
OAuth 2.0 and OpenID Connect: Implementing secure authentication and authorization protocols for user login and access control.
JSON Web Tokens (JWT): Utilizing JWTs to securely transmit information between parties, ensuring data integrity and authenticity.
9. Content Management Systems (CMS) Integration:
Headless CMS: Integrating headless CMS like Contentful or Strapi, allowing content creators to manage content independently from the application's front end.
10. Automated Performance Optimization:
Lighthouse and Web Vitals: Utilizing tools like Lighthouse and Google's Web Vitals to measure and optimize web performance, focusing on key user-centric metrics like loading speed and interactivity.
11. Machine Learning and AI Integration:
TensorFlow.js and ONNX.js: Integrating machine learning models directly into web applications for tasks like image recognition, language processing, and recommendation systems.
12. Cross-Platform Development with Electron:
Electron: Building cross-platform desktop applications using web technologies (HTML, CSS, JavaScript), allowing developers to create desktop apps for Windows, macOS, and Linux.
13. Advanced Database Techniques:
Database Sharding: Implementing database sharding techniques to distribute large databases across multiple servers, improving scalability and performance.
Full-Text Search and Indexing: Implementing full-text search capabilities and optimized indexing for efficient searching and data retrieval.
14. Chaos Engineering:
Chaos Engineering: Introducing controlled experiments to identify weaknesses and potential failures in the system, ensuring the application's resilience and reliability.
15. Serverless Architectures with AWS Lambda or Azure Functions:
Serverless Architectures: Building applications as a collection of small, single-purpose functions that run in a serverless environment, providing automatic scaling and cost efficiency.
16. Data Pipelines and ETL (Extract, Transform, Load) Processes:
Data Pipelines: Creating automated data pipelines for processing and transforming large volumes of data, integrating various data sources and ensuring data consistency.
17. Responsive Design and Accessibility:
Responsive Design: Implementing advanced responsive design techniques for seamless user experiences across a variety of devices and screen sizes.
Accessibility: Ensuring web applications are accessible to all users, including those with disabilities, by following WCAG guidelines and ARIA practices.
full stack development training in Pune
2 notes
·
View notes
Text
The Power of AI and Human Collaboration in Media Content Analysis

In today’s world binge watching has become a way of life not just for Gen-Z but also for many baby boomers. Viewers are watching more content than ever. In particular, Over-The-Top (OTT) and Video-On-Demand (VOD) platforms provide a rich selection of content choices anytime, anywhere, and on any screen. With proliferating content volumes, media companies are facing challenges in preparing and managing their content. This is crucial to provide a high-quality viewing experience and better monetizing content.
Some of the use cases involved are,
Finding opening of credits, Intro start, Intro end, recap start, recap end and other video segments
Choosing the right spots to insert advertisements to ensure logical pause for users
Creating automated personalized trailers by getting interesting themes from videos
Identify audio and video synchronization issues
While these approaches were traditionally handled by large teams of trained human workforces, many AI based approaches have evolved such as Amazon Rekognition’s video segmentation API. AI models are getting better at addressing above mentioned use cases, but they are typically pre-trained on a different type of content and may not be accurate for your content library. So, what if we use AI enabled human in the loop approach to reduce cost and improve accuracy of video segmentation tasks.
In our approach, the AI based APIs can provide weaker labels to detect video segments and send for review to be trained human reviewers for creating picture perfect segments. The approach tremendously improves your media content understanding and helps generate ground truth to fine-tune AI models. Below is workflow of end-2-end solution,
Raw media content is uploaded to Amazon S3 cloud storage. The content may need to be preprocessed or transcoded to make it suitable for streaming platform (e.g convert to .mp4, upsample or downsample)
AWS Elemental MediaConvert transcodes file-based content into live stream assets quickly and reliably. Convert content libraries of any size for broadcast and streaming. Media files are transcoded to .mp4 format
Amazon Rekognition Video provides an API that identifies useful segments of video, such as black frames and end credits.
Objectways has developed a Video segmentation annotator custom workflow with SageMaker Ground Truth labeling service that can ingest labels from Amazon Rekognition. Optionally, you can skip step#3 if you want to create your own labels for training custom ML model or applying directly to your content.
The content may have privacy and digitial rights management requirements and protection. The Objectway’s Video Segmentaton tool also supports Digital Rights Management provider integration to ensure only authorized analyst can look at the content. Moreover, the content analysts operate out of SOC2 TYPE2 compliant facilities where no downloads or screen capture are allowed.
The media analysts at Objectways’ are experts in content understanding and video segmentation labeling for a variety of use cases. Depending on your accuracy requirements, each video can be reviewed or annotated by two independent analysts and segment time codes difference thresholds are used for weeding out human bias (e.g., out of consensus if time code differs by 5 milliseconds). The out of consensus labels can be adjudicated by senior quality analyst to provide higher quality guarantees.
The Objectways Media analyst team provides throughput and quality gurantees and continues to deliver daily throughtput depending on your business needs. The segmented content labels are then saved to Amazon S3 as JSON manifest format and can be directly ingested into your Media streaming platform.
Conclusion
Artificial intelligence (AI) has become ubiquitous in Media and Entertainment to improve content understanding to increase user engagement and also drive ad revenue. The AI enabled Human in the loop approach outlined is best of breed solution to reduce the human cost and provide highest quality. The approach can be also extended to other use cases such as content moderation, ad placement and personalized trailer generation.
Contact [email protected] for more information.
2 notes
·
View notes
Text
What is Solr – Comparing Apache Solr vs. Elasticsearch

In the world of search engines and data retrieval systems, Apache Solr and Elasticsearch are two prominent contenders, each with its strengths and unique capabilities. These open-source, distributed search platforms play a crucial role in empowering organizations to harness the power of big data and deliver relevant search results efficiently. In this blog, we will delve into the fundamentals of Solr and Elasticsearch, highlighting their key features and comparing their functionalities. Whether you're a developer, data analyst, or IT professional, understanding the differences between Solr and Elasticsearch will help you make informed decisions to meet your specific search and data management needs.
Overview of Apache Solr
Apache Solr is a search platform built on top of the Apache Lucene library, known for its robust indexing and full-text search capabilities. It is written in Java and designed to handle large-scale search and data retrieval tasks. Solr follows a RESTful API approach, making it easy to integrate with different programming languages and frameworks. It offers a rich set of features, including faceted search, hit highlighting, spell checking, and geospatial search, making it a versatile solution for various use cases.
Overview of Elasticsearch
Elasticsearch, also based on Apache Lucene, is a distributed search engine that stands out for its real-time data indexing and analytics capabilities. It is known for its scalability and speed, making it an ideal choice for applications that require near-instantaneous search results. Elasticsearch provides a simple RESTful API, enabling developers to perform complex searches effortlessly. Moreover, it offers support for data visualization through its integration with Kibana, making it a popular choice for log analysis, application monitoring, and other data-driven use cases.
Comparing Solr and Elasticsearch
Data Handling and Indexing
Both Solr and Elasticsearch are proficient at handling large volumes of data and offer excellent indexing capabilities. Solr uses XML and JSON formats for data indexing, while Elasticsearch relies on JSON, which is generally considered more human-readable and easier to work with. Elasticsearch's dynamic mapping feature allows it to automatically infer data types during indexing, streamlining the process further.
Querying and Searching
Both platforms support complex search queries, but Elasticsearch is often regarded as more developer-friendly due to its clean and straightforward API. Elasticsearch's support for nested queries and aggregations simplifies the process of retrieving and analyzing data. On the other hand, Solr provides a range of query parsers, allowing developers to choose between traditional and advanced syntax options based on their preference and familiarity.
Scalability and Performance
Elasticsearch is designed with scalability in mind from the ground up, making it relatively easier to scale horizontally by adding more nodes to the cluster. It excels in real-time search and analytics scenarios, making it a top choice for applications with dynamic data streams. Solr, while also scalable, may require more effort for horizontal scaling compared to Elasticsearch.
Community and Ecosystem
Both Solr and Elasticsearch boast active and vibrant open-source communities. Solr has been around longer and, therefore, has a more extensive user base and established ecosystem. Elasticsearch, however, has gained significant momentum over the years, supported by the Elastic Stack, which includes Kibana for data visualization and Beats for data shipping.
Document-Based vs. Schema-Free
Solr follows a document-based approach, where data is organized into fields and requires a predefined schema. While this provides better control over data, it may become restrictive when dealing with dynamic or constantly evolving data structures. Elasticsearch, being schema-free, allows for more flexible data handling, making it more suitable for projects with varying data structures.
Conclusion
In summary, Apache Solr and Elasticsearch are both powerful search platforms, each excelling in specific scenarios. Solr's robustness and established ecosystem make it a reliable choice for traditional search applications, while Elasticsearch's real-time capabilities and seamless integration with the Elastic Stack are perfect for modern data-driven projects. Choosing between the two depends on your specific requirements, data complexity, and preferred development style. Regardless of your decision, both Solr and Elasticsearch can supercharge your search and analytics endeavors, bringing efficiency and relevance to your data retrieval processes.
Whether you opt for Solr, Elasticsearch, or a combination of both, the future of search and data exploration remains bright, with technology continually evolving to meet the needs of next-generation applications.
2 notes
·
View notes
Text
You can learn NodeJS easily, Here's all you need:
1.Introduction to Node.js
• JavaScript Runtime for Server-Side Development
• Non-Blocking I/0
2.Setting Up Node.js
• Installing Node.js and NPM
• Package.json Configuration
• Node Version Manager (NVM)
3.Node.js Modules
• CommonJS Modules (require, module.exports)
• ES6 Modules (import, export)
• Built-in Modules (e.g., fs, http, events)
4.Core Concepts
• Event Loop
• Callbacks and Asynchronous Programming
• Streams and Buffers
5.Core Modules
• fs (File Svstem)
• http and https (HTTP Modules)
• events (Event Emitter)
• util (Utilities)
• os (Operating System)
• path (Path Module)
6.NPM (Node Package Manager)
• Installing Packages
• Creating and Managing package.json
• Semantic Versioning
• NPM Scripts
7.Asynchronous Programming in Node.js
• Callbacks
• Promises
• Async/Await
• Error-First Callbacks
8.Express.js Framework
• Routing
• Middleware
• Templating Engines (Pug, EJS)
• RESTful APIs
• Error Handling Middleware
9.Working with Databases
• Connecting to Databases (MongoDB, MySQL)
• Mongoose (for MongoDB)
• Sequelize (for MySQL)
• Database Migrations and Seeders
10.Authentication and Authorization
• JSON Web Tokens (JWT)
• Passport.js Middleware
• OAuth and OAuth2
11.Security
• Helmet.js (Security Middleware)
• Input Validation and Sanitization
• Secure Headers
• Cross-Origin Resource Sharing (CORS)
12.Testing and Debugging
• Unit Testing (Mocha, Chai)
• Debugging Tools (Node Inspector)
• Load Testing (Artillery, Apache Bench)
13.API Documentation
• Swagger
• API Blueprint
• Postman Documentation
14.Real-Time Applications
• WebSockets (Socket.io)
• Server-Sent Events (SSE)
• WebRTC for Video Calls
15.Performance Optimization
• Caching Strategies (in-memory, Redis)
• Load Balancing (Nginx, HAProxy)
• Profiling and Optimization Tools (Node Clinic, New Relic)
16.Deployment and Hosting
• Deploying Node.js Apps (PM2, Forever)
• Hosting Platforms (AWS, Heroku, DigitalOcean)
• Continuous Integration and Deployment-(Jenkins, Travis CI)
17.RESTful API Design
• Best Practices
• API Versioning
• HATEOAS (Hypermedia as the Engine-of Application State)
18.Middleware and Custom Modules
• Creating Custom Middleware
• Organizing Code into Modules
• Publish and Use Private NPM Packages
19.Logging
• Winston Logger
• Morgan Middleware
• Log Rotation Strategies
20.Streaming and Buffers
• Readable and Writable Streams
• Buffers
• Transform Streams
21.Error Handling and Monitoring
• Sentry and Error Tracking
• Health Checks and Monitoring Endpoints
22.Microservices Architecture
• Principles of Microservices
• Communication Patterns (REST, gRPC)
• Service Discovery and Load Balancing in Microservices
1 note
·
View note
Text
System Shock 2 in Unreal Engine 5
Tools, tools, tools
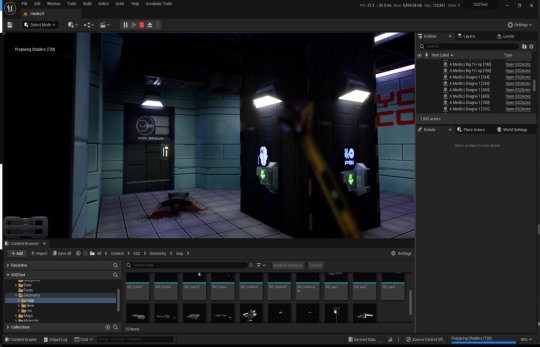
Back when I worked in the games industry, I was a tools guy by trade. It was a bit of a mix between developing APIs and toolkits for other developers, designing database frontends and automated scripts to visualise memory usage in a game's world, or reverse engineering obscure file formats to create time-saving gadgets for art creation.
I still tend to do a lot of that now in my spare time to relax and unwind, whether it's figuring out the binary data and protocols that makes up the art and assets from my favourite games, or recreating systems and solutions for the satisfaction of figuring it all out.
A Shock to the System
A while back I spent a week or so writing importer tools, logic systems and some basic functionality to recreate System Shock 2 in Unreal Engine 5. It got to the stage where importing the data from the game was a one-click process - I clicked import and could literally run around the game in UE5 within seconds, story-missions and ship systems all working.
Most of Dark engine's logic is supported but I haven't had the time to implement AI or enemies yet. Quite a bit of 3D art is still a bit sketchy, too. The craziest thing to me is that there are no light entities or baked lightmaps placed in the levels. All the illumination you can feast your eyes on is Lumen's indirect lighting from the emissive textures I'd dropped into the game. It has been a fun little exercise in getting me back into Unreal Engine development and I've learnt a lot of stuff as usual.
Here is a video of me playing all the way up to the ops deck (and then getting lost before I decided to cut the video short - it's actually possible to all the way through the game now). Lots of spoilers in this video, obviously, for those that haven't played the game.
youtube
What it is
At it's core, it's just a recreation of the various logic-subsystems in System Shock 2 and an assortment of art that has been crudely bashed into Unreal Engine 5. Pretty much all the textures, materials, meshes and maps are converted over and most of the work remaining is just tying them together with bits of C++ string. I hope you also appreciate that I sprinkled on some motion-blur and depth of field to enhance the gameplay a little. Just kidding - I just didn't get around to turning that off in the prefab Unreal Engine template I regularly use.
Tool-wise, it's a mishmash of different things working together:
There's an asset converter that organises the art into an Unreal-Engine-compatible pipeline. It's a mix of Python scripting, mind numbingly dull NodeJS and 3dsmaxscript that juggles data. It recreates all the animated (and inanimate) textures as Unreal materials, meshifies and models the map of the ship, and processes the objects and items into file formats that can be read by the engine.
A DB to Unreal converter takes in DarkDBs and spits out JSON that Unreal Engine and my other tools can understand and then brings it into the Engine. This is the secret sauce that takes all the levels and logic from the original game and recreates it in the Unreal-Dark-hybrid-of-an-engine. It places the logical boundaries for rooms and traps, lays down all the objects (and sets their properties) and keys in those parameters to materialise the missions and set up the story gameplay.
Another tool also weeds through the JSON thats been spat out previously and weaves it into complex databases in Unreal Engine. This arranges all the audio logs, mission texts and more into organised collections that can be referenced and relayed through the UI.
The last part is the Unreal Engine integration. This is the actual recreation of much of the Dark Engine in UE, ranging all the way from the PDA that powers the player's journey through the game, to the traps, buttons and systems that bring the Von Braun to life. It has save-game systems to store the state of objects, inventories and all your stats, levels and progress. This is all C++ and is built in a (hopefully) modular way that I can build on easily should the project progress.
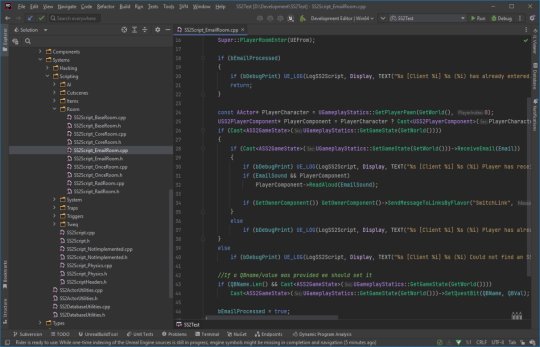
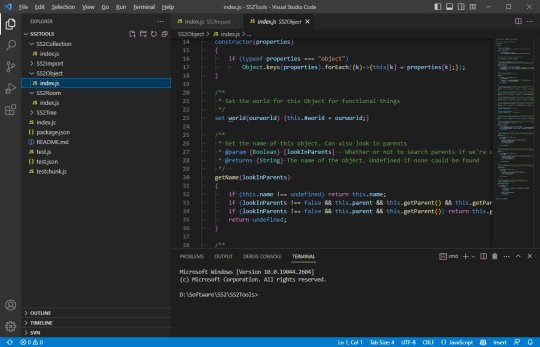
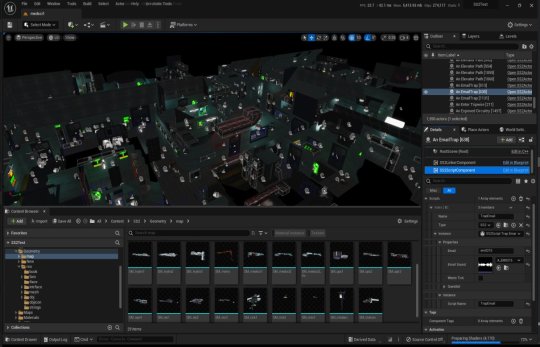
Where it's at
As I mentioned, the levels themselves are a one-click import process. Most of Dark engine's logic, quirks and all, is implemented now (level persistence and transitions, links, traps, triggers, questvars, stats and levelling, inventory, signals/responses, PDA, hacking, etc.) but I still haven't got around to any kid of AI yet. I haven't bought much in the way of animation in from the original game yet, either, as I need to work out the best way to do it. I need to pull together the separate systems and fix little bugs here and there and iron it out with a little testing at some point.
Lighting-wise, this is all just Lumen and emissive textures. I don't think it'll ever not impress me how big of a step forward this is in terms of realistic lighting. No baking of lightmaps, no manually placing lighting. It's all just emissive materials, global/indirect illumination and bounce lighting. It gets a little overly dark here and there (a mixture of emissive textures not quite capturing the original baked lighting, and a limitation in Lumen right now for cached surfaces on complex meshes, aka the level) so could probably benefit with a manual pass at some point, but 'ain't nobody got time for that for a spare-time project.
The unreal editor showcasing some of the systems and levels.
Where it's going
I kind of need to figure out exactly what I'm doing with this project and where to stop. My initial goal was just to have an explorable version of the Von Braun in Unreal Engine 5 to sharpen my game dev skills and stop them from going rusty, but it's gotten a bit further than that now. I'm also thinking of doing something much more in-depth video/blog-wise in some way - let me know in the comments if that's something you'd be interested in and what kind of stuff you'd want to see/hear about.
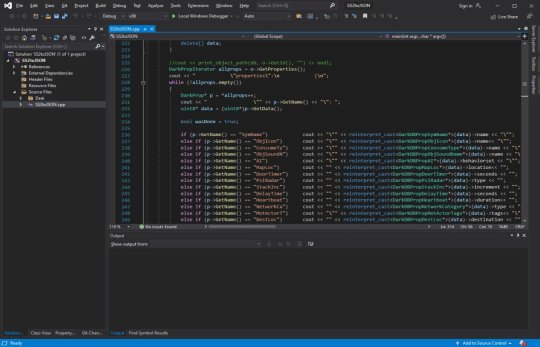
The DB to JSON tool that churns out System Shock 2 game data as readable info
Anyway - I began to expand out with the project and recreate assets and art to integrate into Unreal Engine 5. I'll add more as I get more written up.
#game development#development#programming#video game art#3ds max#retro gaming#unreal engine#ue5#indiedev#unreal engine 5#unreal editor#system shock 2#system shock#dark engine#remake#conversion#visual code#c++#json#javascript#nodejs#tools#game tools#Youtube
1 note
·
View note
Text
Built-in Logging with Serilog: How EasyLaunchpad Keeps Debugging Clean and Insightful

Debugging shouldn’t be a scavenger hunt.
When things break in production or behave unexpectedly in development, you don’t have time to dig through vague error messages or guess what went wrong. That’s why logging is one of the most critical — but often neglected — parts of building robust applications.
With EasyLaunchpad, logging is not an afterthought.
We’ve integrated Serilog, a powerful and structured logging framework for .NET, directly into the boilerplate so developers can monitor, debug, and optimize their apps from day one.
In this post, we’ll explain how Serilog is implemented inside EasyLaunchpad, why it’s a developer favorite, and how it helps you launch smarter and maintain easier.
🧠 Why Logging Matters (Especially in Startups)
Whether you’re launching a SaaS MVP or maintaining a production application, logs are your eyes and ears:
Track user behavior
Monitor background job status
Catch and analyze errors
Identify bottlenecks or API failures
Verify security rules and access patterns
With traditional boilerplates, you often need to configure and wire this up yourself. But EasyLaunchpad comes preloaded with structured, scalable logging using Serilog, so you’re ready to go from the first line of code.
🔧 What Is Serilog?
Serilog is one of the most popular logging libraries for .NET Core. Unlike basic logging tools that write unstructured plain-text logs, Serilog generates structured logs — which are easier to search, filter, and analyze in any environment.
It supports:
JSON log output
File, Console, or external sinks (like Seq, Elasticsearch, Datadog)
Custom formats and enrichers
Log levels: Information, Warning, Error, Fatal, and more
Serilog is lightweight, flexible, and production-proven — ideal for modern web apps like those built with EasyLaunchpad.
🚀 How Serilog Is Integrated in EasyLaunchpad

When you start your EasyLaunchpad-based project, Serilog is already:
Installed via NuGet
Configured via appsettings.json
Injected into the middleware pipeline
Wired into all key services (auth, jobs, payments, etc.)
🔁 Configuration Example (appsettings.json):
“Serilog”: {
“MinimumLevel”: {
“Default”: “Information”,
“Override”: {
“Microsoft”: “Warning”,
“System”: “Warning”
}
},
“WriteTo”: [
{ “Name”: “Console” },
{
“Name”: “File”,
“Args”: {
“path”: “Logs/log-.txt”,
“rollingInterval”: “Day”
}
}
}
}
This setup gives you daily rotating log files, plus real-time console logs for development mode.
🛠 How It Helps Developers
✅ 1. Real-Time Debugging
During development, logs are streamed to the console. You’ll see:
Request details
Controller actions triggered
Background job execution
Custom messages from your services
This means you can debug without hitting breakpoints or printing Console.WriteLine().
✅ 2. Structured Production Logs
In production, logs are saved to disk in a structured format. You can:
Tail them from the server
Upload them to a logging platform (Seq, Datadog, ELK stack)
Automatically parse fields like timestamp, level, message, exception, etc.
This gives predictable, machine-readable logging — critical for scalable monitoring.
✅ 3. Easy Integration with Background Jobs
EasyLaunchpad uses Hangfire for background job scheduling. Serilog is integrated into:
Job execution logging
Retry and failure logs
Email queue status
Error capturing
No more “silent fails” in background processes — every action is traceable.
✅ 4. Enhanced API Logging (Optional Extension)
You can easily extend the logging to:
Log request/response for APIs
Add correlation IDs
Track user activity (e.g., login attempts, failed validations)
The modular architecture allows you to inject loggers into any service or controller via constructor injection.
🔍 Sample Log Output
Here’s a typical log entry generated by Serilog in EasyLaunchpad:
{
“Timestamp”: “2024–07–10T08:33:21.123Z”,
“Level”: “Information”,
“Message”: “User {UserId} logged in successfully.”,
“UserId”: “5dc95f1f-2cc2–4f8a-ae1b-1d29f2aa387a”
}
This is not just human-readable — it’s machine-queryable.
You can filter logs by UserId, Level, or Timestamp using modern logging dashboards or scripts.
🧱 A Developer-Friendly Logging Foundation
Unlike minimal templates, where you have to integrate logging yourself, EasyLaunchpad is:
Ready-to-use from first launch
Customizable for your own needs
Extendable with any Serilog sink (e.g., database, cloud services, Elasticsearch)
This means you spend less time configuring and more time building and scaling.
🧩 Built-In + Extendable
You can add additional log sinks in minutes:
Log.Logger = new LoggerConfiguration()
.WriteTo.Console()
.WriteTo.File(“Logs/log.txt”)
.WriteTo.Seq(“http://localhost:5341")
.CreateLogger();
Want to log in to:
Azure App Insights?
AWS CloudWatch?
A custom microservice?
Serilog makes it possible, and EasyLaunchpad makes it easy to start.
💼 Real-World Scenarios
Here are some real ways logging helps EasyLaunchpad-based apps:
Use Case and the Benefit
Login attempts — Audit user activity and failed attempts
Payment errors- Track Stripe/Paddle API errors
Email queue- Debug failed or delayed emails
Role assignment- Log admin actions for compliance
Cron jobs- Monitor background jobs in real-time
🧠 Final Thoughts
You can’t fix what you can’t see.
Whether you’re launching an MVP or running a growing SaaS platform, structured logging gives you visibility, traceability, and peace of mind.
EasyLaunchpad integrates Serilog from day one — so you’re never flying blind. You get a clean, scalable logging system with zero setup required.
No more guesswork. Just clarity.
👉 Start building with confidence. Check out EasyLaunchpad at https://easylaunchpad.com and see how production-ready logging fits into your stack.
#Serilog .NET logging#structured logs .NET Core#developer-friendly logging in boilerplate#.net development#saas starter kit#saas development company#app development#.net boilerplate
1 note
·
View note
Text
Integrating Third-Party APIs in .NET Applications
In today’s software landscape, building a great app often means connecting it with services that already exist—like payment gateways, email platforms, or cloud storage. Instead of building every feature from scratch, developers can use third-party APIs to save time and deliver more powerful applications. If you're aiming to become a skilled .NET developer, learning how to integrate these APIs is a must—and enrolling at the Best DotNet Training Institute in Hyderabad, Kukatpally, KPHB is a great place to start.
Why Third-Party APIs Matter
Third-party APIs let developers tap into services built by other companies. For example, if you're adding payments to your app, using a service like Razorpay or Stripe means you don’t have to handle all the complexity of secure transactions yourself. Similarly, APIs from Google, Microsoft, or Facebook can help with everything from login systems to maps and analytics.
These tools don’t just save time—they help teams build better, more feature-rich applications.
.NET Makes API Integration Easy
One of the reasons developers love working with .NET is how well it handles API integration. Using built-in tools like HttpClient, you can make API calls, handle responses, and even deal with errors in a clean and structured way. Plus, with async programming support, these interactions won’t slow down your application.
There are also helpful libraries like RestSharp and features for handling JSON that make working with APIs even smoother.
Smart Tips for Successful Integration
When you're working with third-party APIs, keeping a few best practices in mind can make a big difference:
Keep Secrets Safe: Don’t hard-code API keys—use config files or environment variables instead.
Handle Errors Gracefully: Always check for errors and timeouts. APIs aren't perfect, so plan for the unexpected.
Be Aware of Limits: Many APIs have rate limits. Know them and design your app accordingly.
Use Dependency Injection: For tools like HttpClient, DI helps manage resources and keeps your code clean.
Log Everything: Keep logs of API responses—this helps with debugging and monitoring performance.
Real-World Examples
Here are just a few ways .NET developers use third-party APIs in real applications:
Adding Google Maps to show store locations
Sending automatic emails using SendGrid
Processing online payments through PayPal or Razorpay
Uploading and managing files on AWS S3 or Azure Blob Storage
Conclusion
Third-party APIs are a powerful way to level up your .NET applications. They save time, reduce complexity, and help you deliver smarter features faster. If you're ready to build real-world skills and become job-ready, check out Monopoly IT Solutions—we provide hands-on training that prepares you for success in today’s tech-driven world.
#best dotnet training in hyderabad#best dotnet training in kukatpally#best dotnet training in kphb#best .net full stack training
0 notes